Laten we eens kijken wat een Bloom-filter eigenlijk is:
- Een ruimte-efficiënte probabilistische datastructuur
- Gebruikt om te testen of een element lid is van een verzameling
- Kan valse positieven hebben, maar nooit valse negatieven
- Perfect om onnodige zoekopdrachten te verminderen
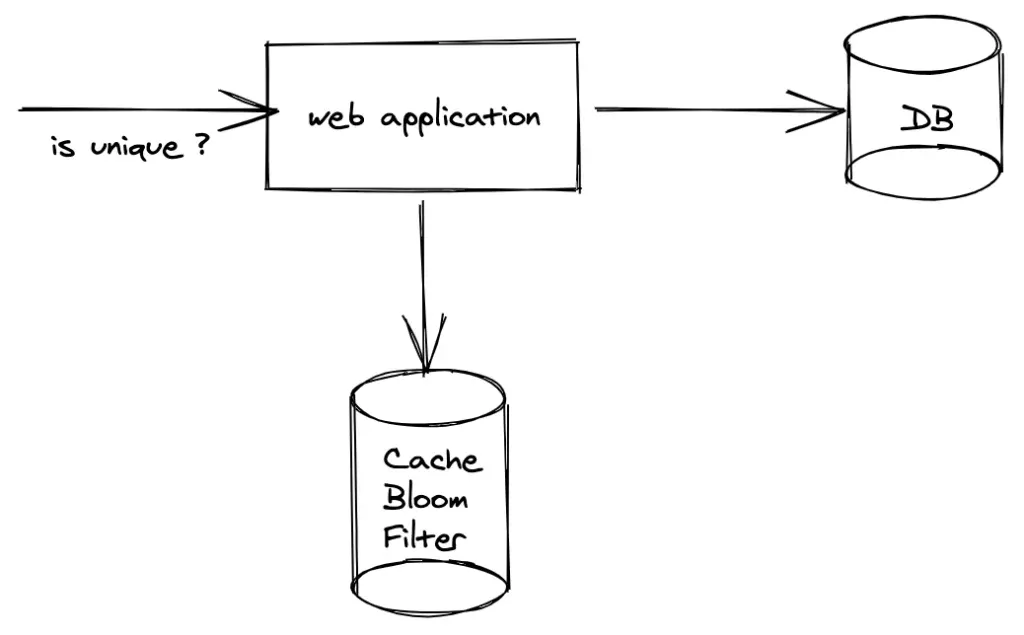
In eenvoudigere termen, het is als een uitsmijter voor je database. Het controleert snel of iets misschien in de club (database) is voordat je daadwerkelijk naar binnen mag om rond te kijken.
Maak kennis met Redis: De Snelle Sidekick
Waarom Redis? Omdat het snel is. Zo snel dat je het mist als je knippert. Het combineren van Bloom-filters met Redis is als een raket aan je al snelle raceauto vastmaken.
Je Redis Bloom-filter instellen
Allereerst moet je de RedisBloom-module installeren. Als je Docker gebruikt, is het zo eenvoudig als:
docker run -p 6379:6379 redislabs/rebloom:latestLaten we nu een basis Bloom-filter in Python implementeren met behulp van de redis-py bibliotheek:
import redis
from redisbloom.client import Client
# Verbinden met Redis
rb = Client(host='localhost', port=6379)
# Maak een Bloom-filter
rb.bfCreate('myfilter', 0.01, 1000000)
# Voeg enkele elementen toe
rb.bfAdd('myfilter', 'element1')
rb.bfAdd('myfilter', 'element2')
# Controleer of elementen bestaan
print(rb.bfExists('myfilter', 'element1')) # True
print(rb.bfExists('myfilter', 'element3')) # False
De Magie Achter de Schermen
Hoe helpt dit eigenlijk om databasequery's te verminderen? Laten we het opsplitsen:
- Controleer het Bloom-filter voordat je je database bevraagt
- Als het filter zegt dat het element niet bestaat, sla de databasequery dan helemaal over
- Als het filter zegt dat het misschien bestaat, ga dan verder met de databasequery
Deze eenvoudige controle kan het aantal onnodige query's drastisch verminderen, vooral voor grote datasets met veel missers.
Praktijkvoorbeeld: Gebruikersauthenticatie
Stel dat je een gebruikersauthenticatiesysteem bouwt. In plaats van de database te raadplegen voor elke inlogpoging met een niet-bestaande gebruikersnaam, kun je een Bloom-filter gebruiken om snel ongeldige gebruikersnamen af te wijzen:
def authenticate_user(username, password):
if not rb.bfExists('users', username):
return "Gebruiker bestaat niet"
# Alleen de database bevragen als de gebruikersnaam mogelijk bestaat
user = db.get_user(username)
if user and user.check_password(password):
return "Authenticatie succesvol"
else:
return "Ongeldige inloggegevens"
Valkuilen en Overwegingen
Voordat je helemaal losgaat met Bloom-filters, houd deze punten in gedachten:
- Valse positieven zijn mogelijk, dus je code moet database-missers gracieus afhandelen
- De grootte van het filter is vast, dus schat je datagrootte nauwkeurig in
- Elementen toevoegen is eenrichtingsverkeer; je kunt geen items uit een Bloom-filter verwijderen
Prestatieverbeteringen: Laat de Cijfers Zien!
Laten we het concreet maken. In een testsituatie met 1 miljoen gebruikers en 10 miljoen inlogpogingen (90% met niet-bestaande gebruikersnamen):
- Zonder Bloom-filter: 10 miljoen databasequery's
- Met Bloom-filter: ~1,9 miljoen databasequery's (81% vermindering!)
Dat is niet zomaar een druppel in de oceaan; het is een vloedgolf van efficiëntie!
Schaaloverwegingen
Naarmate je applicatie groeit, moet je misschien nadenken over:
- Gedistribueerde Bloom-filters over meerdere Redis-instanties
- Periodiek herbouwen van filters om nauwkeurigheid te behouden
- Het monitoren van valse positieven en het aanpassen van filterparameters
Geavanceerde Technieken: Tellen van Bloom-filters
Wil je een stap verder gaan? Bekijk Counting Bloom-filters. Ze maken het mogelijk om elementen te verwijderen en bieden benaderende telquery's. Hier is een snel voorbeeld:
# Maak een Counting Bloom-filter
rb.cfCreate('countingfilter', 1000000)
# Voeg en tel elementen
rb.cfAdd('countingfilter', 'element1')
rb.cfAdd('countingfilter', 'element1')
rb.cfCount('countingfilter', 'element1') # Geeft 2 terug
Afronding
Het implementeren van Bloom-filters in Redis is als het geven van een paar röntgenbrillen aan je database. Het kan door de ruis heen kijken en zich richten op wat echt belangrijk is. Door onnodige query's te verminderen, bespaar je niet alleen verwerkingskracht; je creëert een soepelere, snellere ervaring voor je gebruikers.
Onthoud, in de wereld van high-performance applicaties telt elke milliseconde. Dus waarom geef je je database geen pauze en laat je Redis Bloom-filters wat van het zware werk doen?
Stof tot Nadenken
"De kunst van programmeren is de kunst van het organiseren van complexiteit." - Edsger W. Dijkstra
En soms betekent het organiseren van complexiteit weten wanneer je niet iets moet doen. In dit geval, niet onnodig de database bevragen.
Ga nu en bloei verantwoordelijk!