Graceful degradation draait om het functioneel houden van je systeem, zelfs als het niet op 100% draait. We gaan strategieën verkennen zoals circuit breakers, rate limiting en prioritering om je backend te helpen elke storm te doorstaan. Maak je klaar; het wordt een hobbelige (maar leerzame) rit!
Waarom Zich Bezig Houden met Graceful Degradation?
Laten we eerlijk zijn: in een ideale wereld zouden onze systemen 24/7 perfect draaien. Maar we leven in de echte wereld, waar de wet van Murphy altijd op de loer ligt. Graceful degradation is onze manier om Murphy een hak te zetten en te zeggen: "Leuke poging, maar wij zijn voorbereid."
Dit is waarom het belangrijk is:
- Houdt kritieke functionaliteiten in leven wanneer dingen misgaan
- Voorkomt cascadefouten die je hele systeem kunnen platleggen
- Verbetert de gebruikerservaring tijdens stressvolle periodes
- Geeft je de ruimte om problemen op te lossen zonder een volledige crisis
Strategieën voor Graceful Degradation
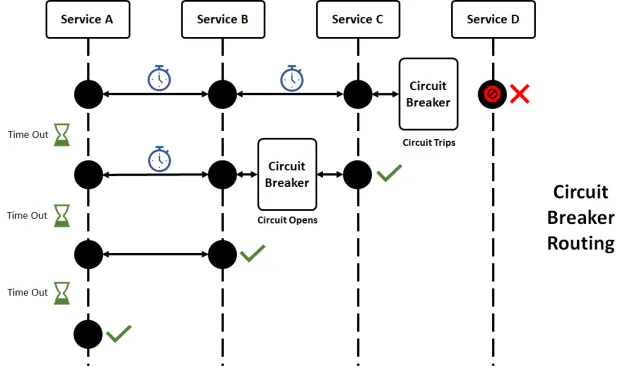
1. Circuit Breakers: De Zekeringkast van Je Systeem
Herinner je je nog dat je als kind een zekering liet doorslaan toen je te veel kerstlampjes aansloot? Circuit breakers in software werken op een vergelijkbare manier, ze beschermen je systeem tegen overbelasting.
Hier is een eenvoudige implementatie met de Hystrix-bibliotheek:
public class ExampleCommand extends HystrixCommand {
private final String name;
public ExampleCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"));
this.name = name;
}
@Override
protected String run() {
// Dit kan een API-aanroep of databasequery zijn
return "Hallo " + name + "!";
}
@Override
protected String getFallback() {
return "Hallo Gast!";
}
}
In dit voorbeeld, als de run() methode faalt of te lang duurt, treedt de circuit breaker in werking en roept getFallback() aan. Het is als een noodgenerator voor je code!
2. Rate Limiting: Je API Wat Manieren Leren
Rate limiting is als een uitsmijter bij een club. Je wilt niet te veel verzoeken tegelijk binnenlaten, anders kan het een rommeltje worden. Hier is hoe je het zou kunnen implementeren met Spring Boot en Bucket4j:
@RestController
public class ApiController {
private final Bucket bucket;
public ApiController() {
Bandwidth limit = Bandwidth.classic(20, Refill.greedy(20, Duration.ofMinutes(1)));
this.bucket = Bucket.builder()
.addLimit(limit)
.build();
}
@GetMapping("/api/resource")
public ResponseEntity getResource() {
if (bucket.tryConsume(1)) {
return ResponseEntity.ok("Hier is je resource!");
}
return ResponseEntity.status(429).body("Te veel verzoeken, probeer het later opnieuw.");
}
}
Deze setup staat 20 verzoeken per minuut toe. Meer dan dat, en je wordt vriendelijk gevraagd om later terug te komen. Het is alsof je API heeft geleerd om in de rij te staan!
3. Prioritering: Niet Alle Verzoeken Zijn Gelijk
Als het moeilijk wordt, moet je weten wat je moet prioriteren. Het is als triage op de spoedeisende hulp – eerst de kritieke operaties, de katten-GIF's later (sorry, kattenliefhebbers).
Overweeg een prioriteitswachtrij voor je verzoeken te implementeren:
public class PriorityRequestQueue {
private PriorityQueue queue;
public PriorityRequestQueue() {
this.queue = new PriorityQueue<>((r1, r2) -> r2.getPriority() - r1.getPriority());
}
public void addRequest(Request request) {
queue.offer(request);
}
public Request processNextRequest() {
return queue.poll();
}
}
Dit zorgt ervoor dat verzoeken met hoge prioriteit (zoals betalingen of kritieke gebruikersacties) als eerste worden verwerkt wanneer de middelen beperkt zijn.
De Kunst van Elegant Falen
Nu we enkele strategieën hebben besproken, laten we het hebben over de kunst van elegant falen. Het gaat niet alleen om het vermijden van een totale ineenstorting; het gaat om het behouden van waardigheid in het aangezicht van tegenspoed. Hier zijn enkele tips:
- Duidelijke Communicatie: Wees transparant met je gebruikers bij het degraderen van diensten. Een simpele "We ervaren een hoge vraag, sommige functies zijn tijdelijk niet beschikbaar" doet wonderen.
- Geleidelijke Degradatie: Ga niet van 100 naar 0. Schakel eerst niet-kritieke functies uit, terwijl je de kernfunctionaliteit zo lang mogelijk intact houdt.
- Intelligente Herhalingen: Implementeer exponentiële backoff voor herhalingen om te voorkomen dat al gestreste diensten worden overbelast.
- Cachingstrategieën: Gebruik caching verstandig om de belasting op backend-diensten tijdens piektijden te verminderen.
Monitoring: Je Vroegtijdige Waarschuwingssysteem
Het implementeren van graceful degradation-strategieën is geweldig, maar hoe weet je wanneer je ze moet activeren? Monitoring is je systeem's vroegtijdige waarschuwingssysteem.
Overweeg het gebruik van tools zoals Prometheus en Grafana om belangrijke statistieken in de gaten te houden:
- Responstijden
- Foutpercentages
- CPU- en geheugengebruik
- Wachtrijlengtes
Stel waarschuwingen in die niet alleen worden geactiveerd wanneer dingen slecht gaan, maar ook wanneer ze er een beetje twijfelachtig uit beginnen te zien. Het is als een weersvoorspelling voor je systeem – je wilt weten over de storm voordat deze toeslaat.
Je Degradatiestrategieën Testen
Je zou geen code implementeren zonder deze te testen, toch? (Toch?!) Hetzelfde geldt voor je degradatiestrategieën. Chaos engineering is de kunst van het opzettelijk breken van dingen.
Tools zoals Chaos Monkey kunnen je helpen om storingen en hoge belasting scenario's in een gecontroleerde omgeving te simuleren. Het is als een brandoefening voor je systeem. Zeker, het kan een beetje zenuwslopend zijn, maar het is beter om erachter te komen dat je sprinklers niet werken tijdens een oefening dan tijdens een echte brand.
Praktijkvoorbeeld: De Aanpak van Netflix
Laten we eens kijken hoe de streaminggigant Netflix omgaat met graceful degradation. Ze gebruiken een techniek genaamd "fallback by priority." Hier is een vereenvoudigde versie van hun aanpak:
- Probeer gepersonaliseerde aanbevelingen voor een gebruiker op te halen.
- Als dat mislukt, val terug op populaire titels voor hun regio.
- Als regionale gegevens niet beschikbaar zijn, toon dan algemene populaire titels.
- Als laatste redmiddel, toon een statische, vooraf gedefinieerde lijst van titels.
Dit zorgt ervoor dat gebruikers altijd iets te zien krijgen, zelfs als het niet de ideale, gepersonaliseerde ervaring is. Het is een geweldig voorbeeld van het degraderen van functionaliteit terwijl er nog steeds waarde wordt geboden.
Conclusie: Omarm de Chaos
Ontwerpen voor graceful degradation gaat niet alleen over het omgaan met storingen; het gaat om het omarmen van de chaotische aard van gedistribueerde systemen. Het is accepteren dat dingen fout zullen gaan en daarop plannen. Het is het verschil tussen zeggen "Oeps, onze fout!" en "We hebben dit onder controle."
Onthoud:
- Implementeer circuit breakers om cascadefouten te voorkomen
- Gebruik rate limiting om hoge belasting scenario's te beheren
- Prioriteer kritieke operaties wanneer middelen schaars zijn
- Communiceer duidelijk met gebruikers tijdens gedegradeerde staten
- Monitor, test en verbeter continu je degradatiestrategieën
Door deze strategieën te volgen, bouw je niet alleen een systeem; je bouwt een veerkrachtige, door de strijd geharde krijger die klaar is om elke chaos die de digitale wereld op hem afstuurt te trotseren. Ga nu en degradeer met gratie!
"De ware test van een systeem is niet hoe het presteert wanneer alles goed gaat, maar hoe het zich gedraagt wanneer alles fout gaat." - Anonieme DevOps Filosoof
Heb je verhalen over graceful degradation in je systemen? Deel ze in de reacties! Immers, de nachtmerrie van de ene ontwikkelaar is de leermogelijkheid van een ander. Veel programmeerplezier, en moge je systemen altijd met gratie en stijl degraderen!