We gaan een backend bouwen die de kracht van Large Language Models (LLMs) combineert met de precisie van vector databases met behulp van LangChain. Het resultaat? Een API die context kan begrijpen, relevante informatie kan ophalen en direct mensachtige antwoorden kan genereren. Het is niet alleen slim; het is angstaanjagend slim.
De RAG Revolutie: Waarom Zou Het Je Moeten Boeien?
Voordat we aan de slag gaan met coderen, laten we eens kijken waarom RAG zoveel opschudding veroorzaakt in de AI-wereld:
- Context is Koning: RAG-systemen begrijpen en benutten context beter dan traditionele zoekopdrachten op basis van trefwoorden.
- Vers en Relevant: In tegenstelling tot statische LLMs kan RAG toegang krijgen tot en gebruikmaken van actuele informatie.
- Vermindering van Hallucinaties: Door antwoorden te baseren op opgehaalde gegevens helpt RAG om die vervelende AI-hallucinaties te verminderen.
- Schaalbaarheid: Naarmate je gegevens groeien, groeit ook de kennis van je AI zonder dat er constant opnieuw getraind hoeft te worden.
De Tech Stack: Onze Keuze aan Wapens
We gaan niet onvoorbereid de strijd aan. Hier is ons arsenaal:
- LangChain: Ons Zwitsers zakmes voor LLM-operaties (oeps, ik had beloofd die uitdrukking niet te gebruiken, toch?)
- Vector Database: We gebruiken Pinecone, maar voel je vrij om je favoriet te kiezen
- LLM: OpenAI's GPT-3.5 of GPT-4 (of een andere LLM die je verkiest)
- FastAPI: Voor het bouwen van onze razendsnelle API-eindpunten
- Python: Omdat, nou ja, het is Python
De Speelplaats Inrichten
Laten we eerst onze omgeving gereedmaken. Start je terminal en installeer de benodigde pakketten:
pip install langchain pinecone-client openai fastapi uvicorn
Nu gaan we een basisstructuur voor een FastAPI-app maken:
from fastapi import FastAPI
from langchain import OpenAI, VectorDBQA
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
import pinecone
import os
app = FastAPI()
# Pinecone initialiseren
pinecone.init(api_key=os.getenv("PINECONE_API_KEY"), environment=os.getenv("PINECONE_ENV"))
# OpenAI initialiseren
llm = OpenAI(temperature=0.7)
# Embeddings initialiseren
embeddings = OpenAIEmbeddings()
# Pinecone vector store initialiseren
index_name = "your-pinecone-index-name"
vectorstore = Pinecone.from_existing_index(index_name, embeddings)
# De QA-keten initialiseren
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", vectorstore=vectorstore)
@app.get("/")
async def root():
return {"message": "Welkom bij de RAG-aangedreven API!"}
@app.get("/query")
async def query(q: str):
result = qa.run(q)
return {"result": result}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Uiteenrafelen: Wat Gebeurt Hier?
Laten we deze code ontleden alsof het een kikker in een biologieles is (maar dan veel spannender):
- We zetten FastAPI op als ons webframework.
- LangChain's
OpenAIklasse is onze toegangspoort tot de LLM. VectorDBQAis de toverstaf die onze vector database combineert met de LLM voor vraag-en-antwoord.- We gebruiken Pinecone als onze vector database, maar je kunt dit vervangen door alternatieven zoals Weaviate of Milvus.
- Het
/queryeindpunt is waar de RAG-magie gebeurt. Het neemt een vraag, voert deze door onze QA-keten en geeft het resultaat terug.
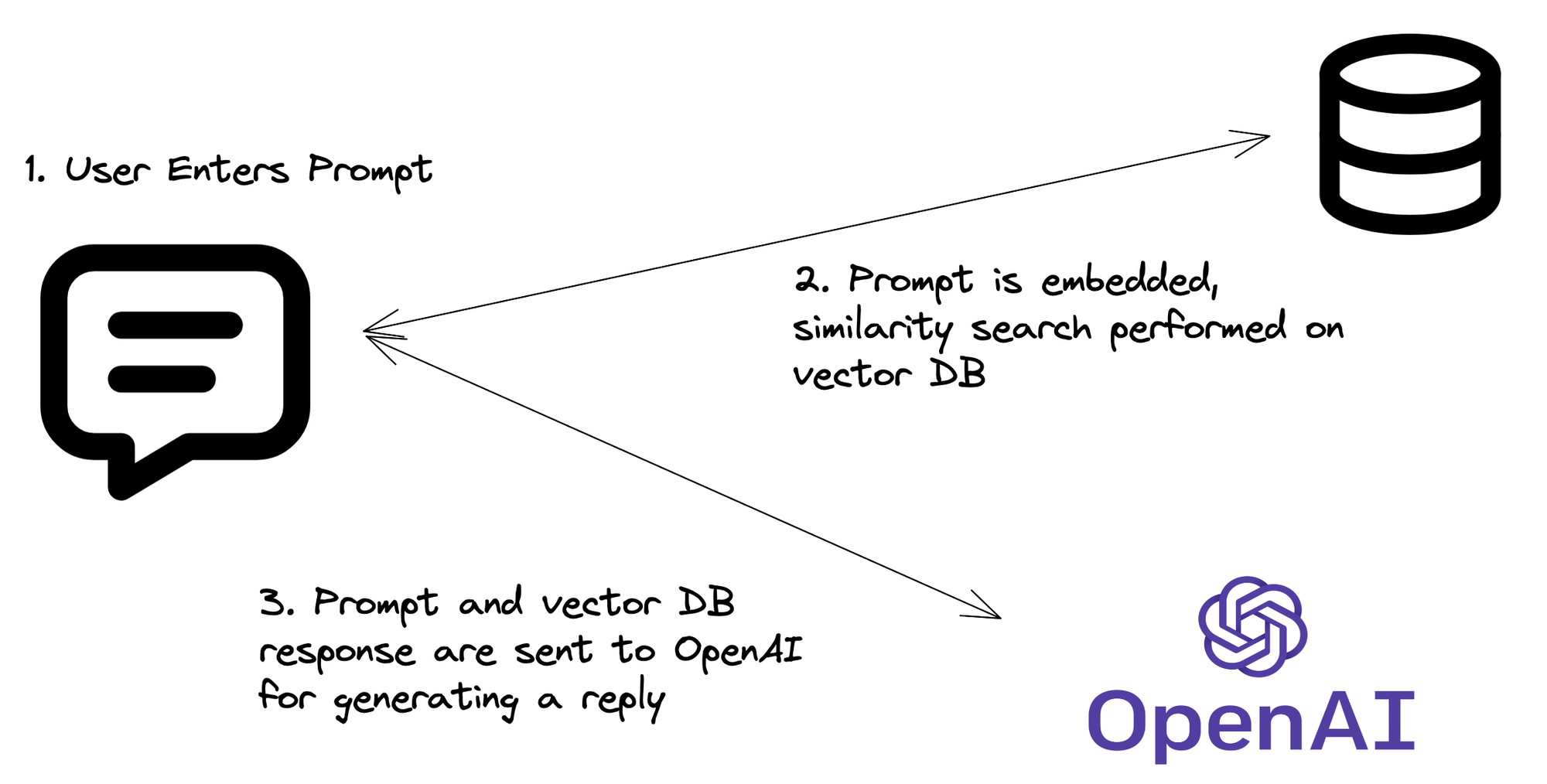
De RAG-Pijplijn: Hoe Het Eigenlijk Werkt
Nu we de code hebben, laten we het RAG-proces uiteenzetten:
- Query Embedding: Je API ontvangt een vraag, die vervolgens wordt omgezet in een vector embedding.
- Vector Zoekopdracht: Deze embedding wordt gebruikt om de Pinecone-index te doorzoeken naar vergelijkbare vectors (d.w.z. relevante informatie).
- Context Ophalen: De meest relevante documenten of stukken worden opgehaald uit Pinecone.
- LLM Magie: De oorspronkelijke vraag en de opgehaalde context worden naar de LLM gestuurd.
- Antwoord Generatie: De LLM genereert een antwoord op basis van de vraag en de opgehaalde context.
- API Terugkeer: Je API stuurt dit intelligente, contextbewuste antwoord terug.
Je RAG Versterken: Geavanceerde Technieken
Klaar om je RAG-systeem van "best cool" naar "wow, dat is geweldig" te brengen? Probeer deze geavanceerde technieken:
1. Hybride Zoekopdracht
Combineer vector zoekopdracht met traditionele trefwoord zoekopdracht voor nog betere resultaten:
from langchain.retrievers import PineconeHybridSearchRetriever
hybrid_retriever = PineconeHybridSearchRetriever(
embeddings=embeddings,
index=vectorstore.pinecone_index
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=hybrid_retriever)
2. Herordenen
Implementeer een herordening stap om je opgehaalde documenten te verfijnen:
from langchain.retrievers import RePhraseQueryRetriever
rephraser = RePhraseQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=rephraser)
3. Streaming Antwoorden
Voor een meer interactieve ervaring, stream je API-antwoorden:
from fastapi import FastAPI, Response
from fastapi.responses import StreamingResponse
@app.get("/stream")
async def stream_query(q: str):
async def event_generator():
for token in qa.run(q):
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
Potentiële Valkuilen: Kijk Uit!
Hoe geweldig RAG ook is, het is niet zonder eigenaardigheden. Hier zijn enkele dingen om op te letten:
- Context Venster Beperkingen: LLMs hebben een maximale contextgrootte. Zorg ervoor dat je opgehaalde documenten deze niet overschrijden.
- Relevantie vs. Diversiteit: Het balanceren van relevante resultaten met diverse informatie kan lastig zijn. Experimenteer met je ophaalparameters.
- Hallucinaties Zijn Niet Verdwenen: Hoewel RAG hallucinaties vermindert, elimineert het ze niet. Implementeer altijd beveiligings- en fact-checking mechanismen.
- API Kosten: Vergeet niet dat elke query mogelijk meerdere API-aanroepen inhoudt (embedding, vector zoekopdracht, LLM). Houd die rekeningen in de gaten!
Afronden: Waarom Dit Belangrijk Is
Het implementeren van RAG in je backend gaat niet alleen over het voorop lopen (hoewel dat een leuke bonus is). Het gaat over het creëren van intelligentere, contextbewuste applicaties die gebruikersvragen kunnen begrijpen en beantwoorden op manieren die voorheen onmogelijk waren.
Door de enorme kennis van LLMs te combineren met de specifieke, actuele informatie in je vector database, creëer je een systeem dat groter is dan de som der delen. Het is alsof je je API een superkracht geeft – het vermogen om te begrijpen, redeneren en mensachtige antwoorden te genereren op basis van realtime gegevens.
"De toekomst is al hier – het is alleen niet gelijkmatig verdeeld." - William Gibson
Nou, nu ben jij een van de gelukkigen met een stukje van die toekomst. Ga en bouw geweldige dingen!
Stof tot Nadenken
Als je RAG in je projecten implementeert, overweeg dan deze vragen:
- Hoe kun je de privacy en veiligheid van de gegevens in je RAG-systeem waarborgen?
- Welke ethische overwegingen spelen een rol bij het inzetten van AI-aangedreven API's?
- Hoe zouden RAG-systemen kunnen evolueren naarmate LLMs en vector databases blijven ontwikkelen?
De antwoorden op deze vragen zullen de toekomst van AI-aangedreven applicaties vormgeven. En nu sta jij aan de voorhoede van die revolutie. Veel succes met coderen!