TL;DR
Het implementeren van idempotente consumenten in Kafka is cruciaal voor het waarborgen van gegevensconsistentie en het voorkomen van dubbele verwerking. We zullen de beste praktijken, veelvoorkomende valkuilen en enkele handige trucs verkennen om je Kafka-consumenten zo idempotent te maken als een wiskundige functie.
Waarom Idempotentie Belangrijk Is
Voordat we in de details duiken, laten we snel herhalen waarom we ons überhaupt met idempotentie bezighouden:
- Voorkomt dubbele verwerking van berichten
- Zorgt voor gegevensconsistentie in je systeem
- Bespaar je van nachtelijke debugsessies en frustratie
- Maakt je systeem veerkrachtiger tegen fouten en herhalingen
Nu we allemaal op dezelfde golflengte zitten, laten we in de goede dingen duiken!
Beste Praktijken voor het Implementeren van Idempotente Consumenten
1. Gebruik Unieke Berichtidentificaties
De eerste regel van de Idempotente Consumentenclub is: Gebruik altijd unieke berichtidentificaties. (De tweede regel is... nou ja, je snapt het wel.)
Het implementeren hiervan is eenvoudig:
public class KafkaMessage {
private String id;
private String payload;
// ... andere velden en methoden
}
public class IdempotentConsumer {
private Set processedMessageIds = new HashSet<>();
public void consume(KafkaMessage message) {
if (processedMessageIds.add(message.getId())) {
// Verwerk het bericht
processMessage(message);
} else {
// Bericht al verwerkt, overslaan
log.info("Duplicaat bericht overslaan: {}", message.getId());
}
}
}
Pro tip: Gebruik UUID's of een combinatie van topic, partition en offset voor je bericht-ID's. Het is alsof je elk bericht zijn eigen unieke sneeuwvlokpatroon geeft!
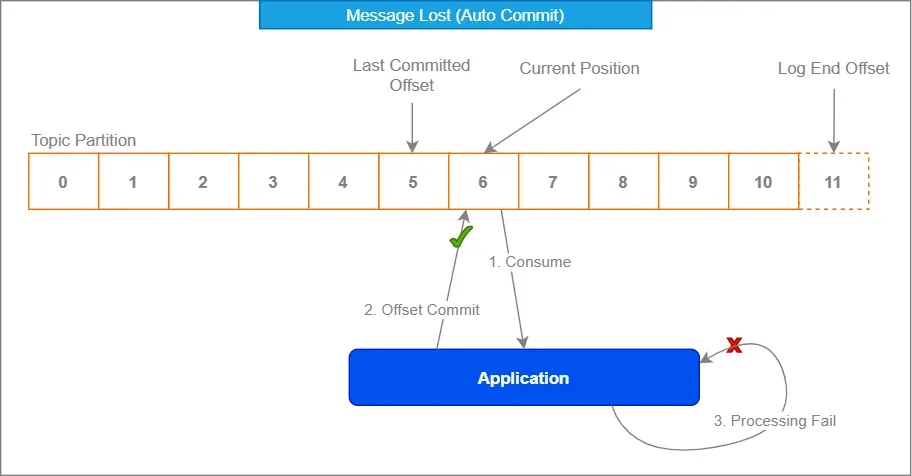
2. Maak Gebruik van Kafka's Offset Management
Kafka's ingebouwde offset management is je vriend. Omarm het zoals die rare oom op familiebijeenkomsten – het lijkt misschien ongemakkelijk in het begin, maar het heeft je rug.
Properties props = new Properties();
props.put("enable.auto.commit", "false");
props.put("isolation.level", "read_committed");
KafkaConsumer consumer = new KafkaConsumer<>(props);
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
processRecord(record);
}
consumer.commitSync();
}
Door auto-commit uit te schakelen en handmatig offsets te committeren na verwerking, zorg je ervoor dat berichten alleen als geconsumeerd worden gemarkeerd wanneer je 100% zeker weet dat ze correct zijn afgehandeld.
3. Implementeer een Deduplicatiestrategie
Soms, ondanks onze beste inspanningen, sluipen duplicaten binnen als sluwe ninja's. Daar komt een solide deduplicatiestrategie van pas.
Overweeg het gebruik van een gedistribueerde cache zoals Redis om verwerkte bericht-ID's op te slaan:
@Service
public class DuplicateChecker {
private final RedisTemplate redisTemplate;
public DuplicateChecker(RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
public boolean isDuplicate(String messageId) {
return !redisTemplate.opsForValue().setIfAbsent(messageId, "processed", Duration.ofDays(1));
}
}
Deze aanpak stelt je in staat om duplicaten te controleren over meerdere consumentinstanties en zelfs na herstarts. Het is alsof je een uitsmijter hebt voor je berichten – "Als je ID niet op de lijst staat, kom je er niet in!"
4. Gebruik Idempotente Operaties
Waar mogelijk, ontwerp je berichtverwerkingsoperaties om van nature idempotent te zijn. Dit betekent dat zelfs als een bericht meerdere keren wordt verwerkt, het eindresultaat niet wordt beïnvloed.
Bijvoorbeeld, in plaats van:
public void incrementCounter(String counterId) {
int currentValue = counterRepository.get(counterId);
counterRepository.set(counterId, currentValue + 1);
}
Overweeg het gebruik van een atomaire operatie:
public void incrementCounter(String counterId) {
counterRepository.increment(counterId);
}
Op deze manier, zelfs als de incrementeeroperatie meerdere keren wordt aangeroepen voor hetzelfde bericht, blijft het eindresultaat hetzelfde.
Veelvoorkomende Valkuilen en Hoe Ze te Vermijden
Nu we de basis hebben behandeld, laten we eens kijken naar enkele veelvoorkomende valkuilen waar zelfs ervaren ontwikkelaars in kunnen vallen:
1. Alleen Vertrouwen op Kafka's "Exactly Once" Semantiek
Hoewel Kafka "exactly once" semantiek biedt, is het geen wondermiddel. Het garandeert alleen precies één keer levering binnen het Kafka-cluster, niet end-to-end precies één keer verwerking in je applicatie.
"Vertrouw, maar verifieer" – Ronald Reagan (waarschijnlijk over Kafka-berichten)
Implementeer altijd je eigen idempotentiecontroles naast de garanties van Kafka.
2. Transactieranden Negeren
Zorg ervoor dat je berichtverwerking en offsetcommits deel uitmaken van dezelfde transactie. Anders kun je in een situatie terechtkomen waarin je een bericht hebt verwerkt maar de offset niet hebt gecommitteerd, wat leidt tot herverwerking bij het opnieuw starten van de consument.
@Transactional
public void processMessage(ConsumerRecord record) {
// Verwerk het bericht
businessLogic.process(record.value());
// Handmatig het bericht erkennen
acknowledgment.acknowledge();
}
3. Databasebeperkingen Over het Hoofd Zien
Als je verwerkte gegevens in een database opslaat, gebruik dan unieke beperkingen in je voordeel. Ze kunnen dienen als een extra beschermingslaag tegen duplicaten.
CREATE TABLE processed_messages (
message_id VARCHAR(255) PRIMARY KEY,
processed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Vervolgens, in je Java-code:
try {
jdbcTemplate.update("INSERT INTO processed_messages (message_id) VALUES (?)", messageId);
// Verwerk het bericht
} catch (DuplicateKeyException e) {
// Bericht al verwerkt, overslaan
}
Geavanceerde Technieken voor de Dappere
Klaar om je idempotente consumentenspel naar een hoger niveau te tillen? Hier zijn enkele geavanceerde technieken voor de durfals:
1. Idempotentiesleutels in Headers
In plaats van te vertrouwen op de inhoud van het bericht voor idempotentie, overweeg het gebruik van Kafka-berichtheaders om idempotentiesleutels op te slaan. Dit maakt flexibelere berichtinhoud mogelijk terwijl idempotentie behouden blijft.
// Producer
ProducerRecord record = new ProducerRecord<>("my-topic", "key", "value");
record.headers().add("idempotency-key", UUID.randomUUID().toString().getBytes());
producer.send(record);
// Consumer
ConsumerRecord record = // ... ontvangen van Kafka
byte[] idempotencyKeyBytes = record.headers().lastHeader("idempotency-key").value();
String idempotencyKey = new String(idempotencyKeyBytes, StandardCharsets.UTF_8);
2. Tijdgebaseerde Deduplicatie
In sommige scenario's wil je misschien tijdgebaseerde deduplicatie implementeren. Dit is nuttig bij het omgaan met gebeurtenisstromen waarbij dezelfde gebeurtenis na een bepaalde periode legitiem kan worden herhaald.
public class TimeBasedDuplicateChecker {
private final RedisTemplate redisTemplate;
private final Duration deduplicationWindow;
public TimeBasedDuplicateChecker(RedisTemplate redisTemplate, Duration deduplicationWindow) {
this.redisTemplate = redisTemplate;
this.deduplicationWindow = deduplicationWindow;
}
public boolean isDuplicate(String messageId) {
String key = "dedup:" + messageId;
Boolean isNew = redisTemplate.opsForValue().setIfAbsent(key, "processed", deduplicationWindow);
return isNew != null && !isNew;
}
}
3. Idempotente Aggregaties
Bij het omgaan met aggregatieoperaties, overweeg het gebruik van idempotente aggregatietechnieken. Bijvoorbeeld, in plaats van een lopende som op te slaan, sla individuele waarden op en bereken de som ter plekke:
public class IdempotentAggregator {
private final Map values = new ConcurrentHashMap<>();
public void addValue(String key, double value) {
values.put(key, value);
}
public double getSum() {
return values.values().stream().mapToDouble(Double::doubleValue).sum();
}
}
Deze aanpak zorgt ervoor dat zelfs als een bericht meerdere keren wordt verwerkt, het de uiteindelijke aggregatieresultaat niet beïnvloedt.
Afronding
Het implementeren van idempotente consumenten in Kafka lijkt misschien een ontmoedigende taak, maar met deze beste praktijken en technieken, zul je duplicaten als een professional afhandelen in een mum van tijd. Onthoud, de sleutel is om altijd het onverwachte te verwachten en je systeem vanaf de basis met idempotentie in gedachten te ontwerpen.
Hier is een snelle checklist om bij de hand te houden:
- Gebruik unieke berichtidentificaties
- Maak gebruik van Kafka's offset management
- Implementeer een robuuste deduplicatiestrategie
- Ontwerp waar mogelijk van nature idempotente operaties
- Wees je bewust van veelvoorkomende valkuilen en hoe je ze kunt vermijden
- Overweeg geavanceerde technieken voor specifieke use-cases
Door deze richtlijnen te volgen, verbeter je niet alleen de betrouwbaarheid en consistentie van je op Kafka gebaseerde systemen, maar bespaar je jezelf ook talloze uren debuggen en hoofdpijn. En laten we eerlijk zijn, is dat niet waar we allemaal naar streven?
Ga nu op pad en overwin die dubbele berichten! Je toekomstige zelf (en je ops-team) zullen je dankbaar zijn.
"In de wereld van Kafka-consumenten is idempotentie niet zomaar een functie – het is een superkracht." – Een wijze ontwikkelaar (waarschijnlijk)
Veel programmeerplezier, en moge je consumenten altijd idempotent zijn!