In deze diepgaande verkenning gaan we de mouwen opstropen en ons verdiepen in geavanceerde mechanismen voor foutpropagatie. We zullen onderzoeken hoe we een aangepaste fouttolerantielaag kunnen bouwen die de meest hardnekkige fouten kan afhandelen, waardoor je gedistribueerde systeem zo robuust blijft als een Nokia 3310 in een wereld vol kwetsbare smartphones.
Het Foutpropagatie Dilemma
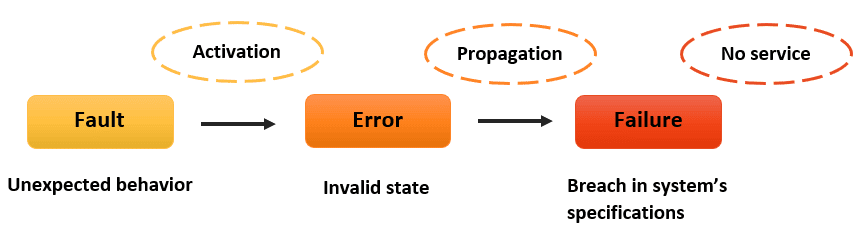
Voordat we naar de oplossing springen, laten we even de tijd nemen om het probleem te begrijpen. In een gedistribueerd systeem zijn fouten als roddelende buren - ze verspreiden zich snel en kunnen behoorlijk wat opschudding veroorzaken als ze niet worden gecontroleerd.
Overweeg dit scenario:
# Service A
def process_order(order_id):
try:
user = get_user_info(order_id)
items = get_order_items(order_id)
payment = process_payment(user, items)
shipping = arrange_shipping(user, items)
return {"status": "success", "order_id": order_id}
except Exception as e:
return {"status": "error", "message": str(e)}
# Service B
def get_user_info(order_id):
# Simuleren van een databasefout
raise DatabaseConnectionError("Kan geen verbinding maken met gebruikersdatabase")
In dit eenvoudige voorbeeld zal een fout in Service B opborrelen naar Service A, wat mogelijk een kettingreactie van storingen kan veroorzaken. Maar wat als we deze fouten konden onderscheppen, analyseren en intelligent reageren? Dat is waar onze aangepaste fouttolerantielaag in beeld komt.
De Fouttolerantielaag Bouwen
Onze fouttolerantielaag zal bestaan uit verschillende belangrijke componenten:
- Foutclassificatiesysteem
- Propagatieregels Engine
- Circuit Breaker Implementatie
- Retry Mechanisme met Exponentiële Backoff
- Fallback Strategieën
Laten we deze één voor één bekijken.
1. Foutclassificatiesysteem
De eerste stap is het classificeren van fouten op basis van hun ernst en potentiële impact. We maken een aangepaste fout hiërarchie:
class BaseError(Exception):
def __init__(self, message, severity):
self.message = message
self.severity = severity
class TransientError(BaseError):
def __init__(self, message):
super().__init__(message, severity="LOW")
class PartialOutageError(BaseError):
def __init__(self, message):
super().__init__(message, severity="MEDIUM")
class CriticalError(BaseError):
def __init__(self, message):
super().__init__(message, severity="HIGH")
Deze classificatie stelt ons in staat om fouten anders te behandelen op basis van hun ernst.
2. Propagatieregels Engine
Vervolgens maken we een regels engine om te beslissen hoe fouten door ons systeem moeten worden gepropageerd:
class PropagationRulesEngine:
def __init__(self):
self.rules = {
TransientError: self.handle_transient,
PartialOutageError: self.handle_partial_outage,
CriticalError: self.handle_critical
}
def handle_error(self, error):
handler = self.rules.get(type(error), self.default_handler)
return handler(error)
def handle_transient(self, error):
# Implementeer retry-logica
pass
def handle_partial_outage(self, error):
# Implementeer fallback-strategie
pass
def handle_critical(self, error):
# Implementeer circuit breaking
pass
def default_handler(self, error):
# Log en propageren
logging.error(f"Onbehandelde fout: {error}")
raise error
Deze engine stelt ons in staat om specifieke gedragingen te definiëren voor verschillende fouttypen.
3. Circuit Breaker Implementatie
Om cascadefouten te voorkomen, implementeren we een circuit breaker patroon:
import time
class CircuitBreaker:
def __init__(self, failure_threshold, reset_timeout):
self.failure_count = 0
self.failure_threshold = failure_threshold
self.reset_timeout = reset_timeout
self.last_failure_time = None
self.state = "CLOSED"
def execute(self, func, *args, **kwargs):
if self.state == "OPEN":
if time.time() - self.last_failure_time > self.reset_timeout:
self.state = "HALF-OPEN"
else:
raise CircuitBreakerOpenError("Circuit is open")
try:
result = func(*args, **kwargs)
if self.state == "HALF-OPEN":
self.state = "CLOSED"
self.failure_count = 0
return result
except Exception as e:
self.failure_count += 1
if self.failure_count >= self.failure_threshold:
self.state = "OPEN"
self.last_failure_time = time.time()
raise e
Deze circuit breaker zal automatisch "trippen" wanneer een bepaald aantal storingen optreedt, waardoor verdere oproepen naar de problematische service worden voorkomen.
4. Retry Mechanisme met Exponentiële Backoff
Voor tijdelijke fouten kan een retry mechanisme met exponentiële backoff zeer nuttig zijn:
import random
import time
def retry_with_backoff(retries=3, backoff_in_seconds=1):
def decorator(func):
def wrapper(*args, **kwargs):
x = 0
while True:
try:
return func(*args, **kwargs)
except TransientError as e:
if x == retries:
raise e
sleep = (backoff_in_seconds * 2 ** x +
random.uniform(0, 1))
time.sleep(sleep)
x += 1
return wrapper
return decorator
@retry_with_backoff(retries=5, backoff_in_seconds=1)
def unreliable_function():
# Simuleren van een onbetrouwbare functie
if random.random() < 0.7:
raise TransientError("Tijdelijke storing")
return "Succes!"
Deze decorator zal de functie automatisch opnieuw proberen met toenemende vertragingen tussen pogingen.
5. Fallback Strategieën
Tot slot implementeren we enkele fallback strategieën voor wanneer alles faalt:
class FallbackStrategy:
def __init__(self):
self.strategies = {
"get_user_info": self.fallback_user_info,
"process_payment": self.fallback_payment,
"arrange_shipping": self.fallback_shipping
}
def execute_fallback(self, function_name, *args, **kwargs):
fallback = self.strategies.get(function_name)
if fallback:
return fallback(*args, **kwargs)
raise NoFallbackError(f"Geen fallback-strategie voor {function_name}")
def fallback_user_info(self, order_id):
# Retourneer gecachte of standaard gebruikersinformatie
return {"user_id": "default", "name": "John Doe"}
def fallback_payment(self, user, items):
# Markeer betaling als in behandeling en ga verder
return {"status": "pending", "message": "Betaling wordt later verwerkt"}
def fallback_shipping(self, user, items):
# Gebruik een standaard verzendmethode
return {"method": "standard", "estimated_delivery": "5-7 werkdagen"}
Deze fallback strategieën bieden een vangnet wanneer normale operaties falen.
Alles Samenbrengen
Nu we alle componenten hebben, laten we zien hoe ze samenwerken in ons gedistribueerde systeem:
class FaultToleranceLayer:
def __init__(self):
self.rules_engine = PropagationRulesEngine()
self.circuit_breaker = CircuitBreaker(failure_threshold=5, reset_timeout=60)
self.fallback_strategy = FallbackStrategy()
def execute(self, func, *args, **kwargs):
try:
return self.circuit_breaker.execute(func, *args, **kwargs)
except Exception as e:
try:
return self.rules_engine.handle_error(e)
except Exception:
return self.fallback_strategy.execute_fallback(func.__name__, *args, **kwargs)
# Gebruik van de fouttolerantielaag
fault_tolerance = FaultToleranceLayer()
@retry_with_backoff(retries=3, backoff_in_seconds=1)
def get_user_info(order_id):
# Eigenlijke implementatie hier
pass
def process_order(order_id):
user = fault_tolerance.execute(get_user_info, order_id)
# Rest van de orderverwerkingslogica
pass
Met deze opzet kan ons systeem een breed scala aan foutscenario's gracieus afhandelen, cascadefouten voorkomen en de algehele betrouwbaarheid verbeteren.
De Beloning: Een Meer Resilient Systeem
Door deze aangepaste fouttolerantielaag te implementeren, hebben we de veerkracht van ons gedistribueerde systeem aanzienlijk verbeterd. Dit is wat we hebben gewonnen:
- Intelligente foutafhandeling op basis van fouttype en ernst
- Automatische herhalingen voor tijdelijke storingen
- Bescherming tegen cascadefouten met circuit breakers
- Gracieus verval door fallback strategieën
- Verbeterde zichtbaarheid in foutpatronen en systeemgedrag
Onthoud dat het bouwen van een fouttolerant gedistribueerd systeem een doorlopend proces is. Blijf het gedrag van je systeem monitoren, verfijn je foutafhandelingsstrategieën en pas je aan aan nieuwe storingsmodi naarmate ze zich voordoen.
Stof tot Nadenken
Als je je eigen fouttolerantielaag implementeert, overweeg dan deze vragen:
- Hoe ga je om met fouten die niet netjes in je classificatiesysteem passen?
- Welke meetwaarden ga je gebruiken om de effectiviteit van je fouttolerantiemechanismen te evalueren?
- Hoe balanceer je de wens naar veerkracht met de behoefte aan systeemresponsiviteit?
- Hoe kun je deze fouttolerantielaag gebruiken om de observeerbaarheid van je systeem te verbeteren?
Onthoud dat in de wereld van gedistribueerde systemen fouten niet alleen onvermijdelijk zijn - ze zijn een kans om je systeem sterker te maken. Veel succes met het afhandelen van fouten!