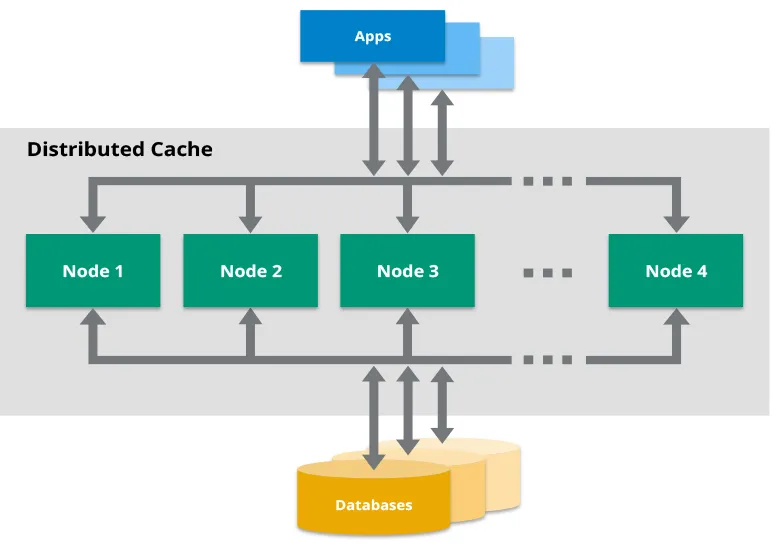
Waarom Hazelcast? En Waarom Zou Het Je Moeten Interesseren?
Voordat we in de details duiken, laten we de grote vraag beantwoorden: Waarom Hazelcast? In de enorme zee van caching-oplossingen valt Hazelcast op als een gedistribueerd in-memory datarooster dat goed samenwerkt met Java. Het is als Redis, maar dan met een Java-eerste benadering en enkele handige functies die gedistribueerde caching in microservices eenvoudig maken.
Hier is een kort overzicht waarom Hazelcast je nieuwe beste vriend zou kunnen worden:
- Natuurlijke Java API (geen gedoe meer met serialisatie)
- Gedistribueerde berekeningen (denk aan MapReduce, maar eenvoudiger)
- Ingebouwde split-brain bescherming (omdat netwerkpartities voorkomen)
- Eenvoudig schalen (voeg gewoon meer nodes toe)
Hazelcast Instellen in Je Microservices
Laten we beginnen met de basis. Het toevoegen van Hazelcast aan je Java microservice is verrassend eenvoudig. Voeg eerst de afhankelijkheid toe aan je pom.xml:
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.1.1</version>
</dependency>
Nu, laten we een eenvoudige Hazelcast-instantie maken:
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class CacheConfig {
public HazelcastInstance hazelcastInstance() {
return Hazelcast.newHazelcastInstance();
}
}
Voilà! Je hebt nu een Hazelcast-node die draait in je microservice. Maar wacht, er is meer!
Geavanceerde Caching Patronen
Nu we de basis hebben behandeld, laten we duiken in enkele geavanceerde caching patronen die je microservices laten schitteren.
1. Read-Through/Write-Through Caching
Dit patroon is als een persoonlijke assistent voor je data. In plaats van handmatig te beheren wat in en uit de cache gaat, kan Hazelcast het voor je doen.
public class UserCacheStore implements MapStore<String, User> {
@Override
public User load(String key) {
// Laden uit database
}
@Override
public void store(String key, User value) {
// Opslaan in database
}
// Andere methoden...
}
MapConfig mapConfig = new MapConfig("users");
mapConfig.setMapStoreConfig(new MapStoreConfig().setImplementation(new UserCacheStore()));
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Met deze setup zal Hazelcast automatisch data uit je database laden wanneer het niet in de cache staat, en data terugschrijven naar de database wanneer het in de cache wordt bijgewerkt. Het is als magie, maar beter omdat het gewoon goed engineering is.
2. Near Cache Patroon
Soms heb je data nodig die razendsnel is, zelfs in een gedistribueerde omgeving. Hier komt het Near Cache patroon in beeld. Het is als een cache voor je cache. Meta, toch?
NearCacheConfig nearCacheConfig = new NearCacheConfig();
nearCacheConfig.setName("users");
nearCacheConfig.setTimeToLiveSeconds(300);
MapConfig mapConfig = new MapConfig("users");
mapConfig.setNearCacheConfig(nearCacheConfig);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Deze setup creëert een lokale cache op elke Hazelcast-node, waardoor netwerkoproepen worden verminderd en leesbewerkingen worden versneld. Het is vooral nuttig voor data die vaak wordt gelezen maar zelden wordt bijgewerkt.
3. Verwijderingsbeleid
Geheugen is kostbaar, vooral in microservices. Hazelcast biedt geavanceerde verwijderingsbeleid om ervoor te zorgen dat je cache geen geheugenverslinder wordt.
MapConfig mapConfig = new MapConfig("users");
mapConfig.setEvictionConfig(
new EvictionConfig()
.setEvictionPolicy(EvictionPolicy.LRU)
.setMaxSizePolicy(MaxSizePolicy.PER_NODE)
.setSize(10000)
);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Deze configuratie stelt een LRU (Least Recently Used) verwijderingsbeleid in, waardoor je cache binnen een limiet van 10.000 items per node blijft. Het is als een uitsmijter voor je dataparty, die de minst populaire items eruit gooit wanneer het te druk wordt.
Gedistribueerde Berekeningen: Naar het Volgende Niveau
Caching is geweldig, maar Hazelcast kan meer. Laten we eens kijken hoe we gedistribueerde berekeningen kunnen benutten om onze microservices te verbeteren.
1. Gedistribueerde Executor Service
Moet je een taak uitvoeren over je hele cluster? Hazelcast's Distributed Executor Service heeft je gedekt.
public class UserAnalytics implements Callable<Map<String, Integer>>, HazelcastInstanceAware {
private transient HazelcastInstance hazelcastInstance;
@Override
public Map<String, Integer> call() {
IMap<String, User> users = hazelcastInstance.getMap("users");
// Analyse uitvoeren op lokale data
return results;
}
@Override
public void setHazelcastInstance(HazelcastInstance hazelcastInstance) {
this.hazelcastInstance = hazelcastInstance;
}
}
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IExecutorService executorService = hz.getExecutorService("analytics-executor");
Set<Member> members = hz.getCluster().getMembers();
Map<Member, Future<Map<String, Integer>>> results = executorService.submitToMembers(new UserAnalytics(), members);
// Resultaten samenvoegen
Map<String, Integer> finalResults = new HashMap<>();
for (Future<Map<String, Integer>> future : results.values()) {
Map<String, Integer> result = future.get();
// Resultaat samenvoegen in finalResults
}
Dit patroon stelt je in staat om berekeningen uit te voeren op data waar het zich bevindt, waardoor databeweging wordt verminderd en prestaties worden verbeterd. Het is als het brengen van de functie naar de data, in plaats van andersom.
2. Entry Processors
Moet je meerdere items in je cache atomair bijwerken? Entry Processors zijn je vriend.
public class UserUpgradeEntryProcessor implements EntryProcessor<String, User, Object> {
@Override
public Object process(Map.Entry<String, User> entry) {
User user = entry.getValue();
if (user.getPoints() > 1000) {
user.setStatus("GOLD");
entry.setValue(user);
}
return null;
}
}
IMap<String, User> users = hz.getMap("users");
users.executeOnEntries(new UserUpgradeEntryProcessor());
Dit patroon stelt je in staat om bewerkingen uit te voeren op meerdere items zonder de noodzaak voor expliciete vergrendeling of transactiebeheer. Het is als een mini-transactie voor elk item in je cache.
Valkuilen om Voorzichtig mee te Zijn
Zoals met elk krachtig hulpmiddel, komt Hazelcast met zijn eigen set van potentiële valkuilen. Hier zijn er een paar om in gedachten te houden:
- Over-caching: Niet alles hoeft te worden gecached. Wees selectief over wat je in Hazelcast plaatst.
- Serialisatie negeren: Hazelcast moet objecten serialiseren. Zorg ervoor dat je objecten serialiseerbaar zijn en overweeg aangepaste serializers voor complexe objecten.
- Monitoring verwaarlozen: Stel goede monitoring in voor je Hazelcast-cluster. Tools zoals Hazelcast Management Center kunnen van onschatbare waarde zijn.
- Consistentie vergeten: In een gedistribueerd systeem is eventual consistency vaak de norm. Ontwerp je applicatie dienovereenkomstig.
Afronding
We hebben veel behandeld, van basisinstellingen tot geavanceerde caching patronen en gedistribueerde berekeningen. Hazelcast is een krachtig hulpmiddel dat de prestaties en schaalbaarheid van je Java microservices aanzienlijk kan verbeteren. Maar onthoud, met grote kracht komt grote verantwoordelijkheid. Gebruik deze patronen verstandig en houd altijd rekening met de specifieke behoeften van je applicatie.
Ga nu en cache als een professional! Je microservices (en je gebruikers) zullen je dankbaar zijn.
"De snelste data-toegang is de data die je helemaal niet hoeft te benaderen." - Onbekende Caching Goeroe (waarschijnlijk)
Verder Lezen
Als je meer wilt weten, bekijk dan deze bronnen:
Veel cacheplezier!