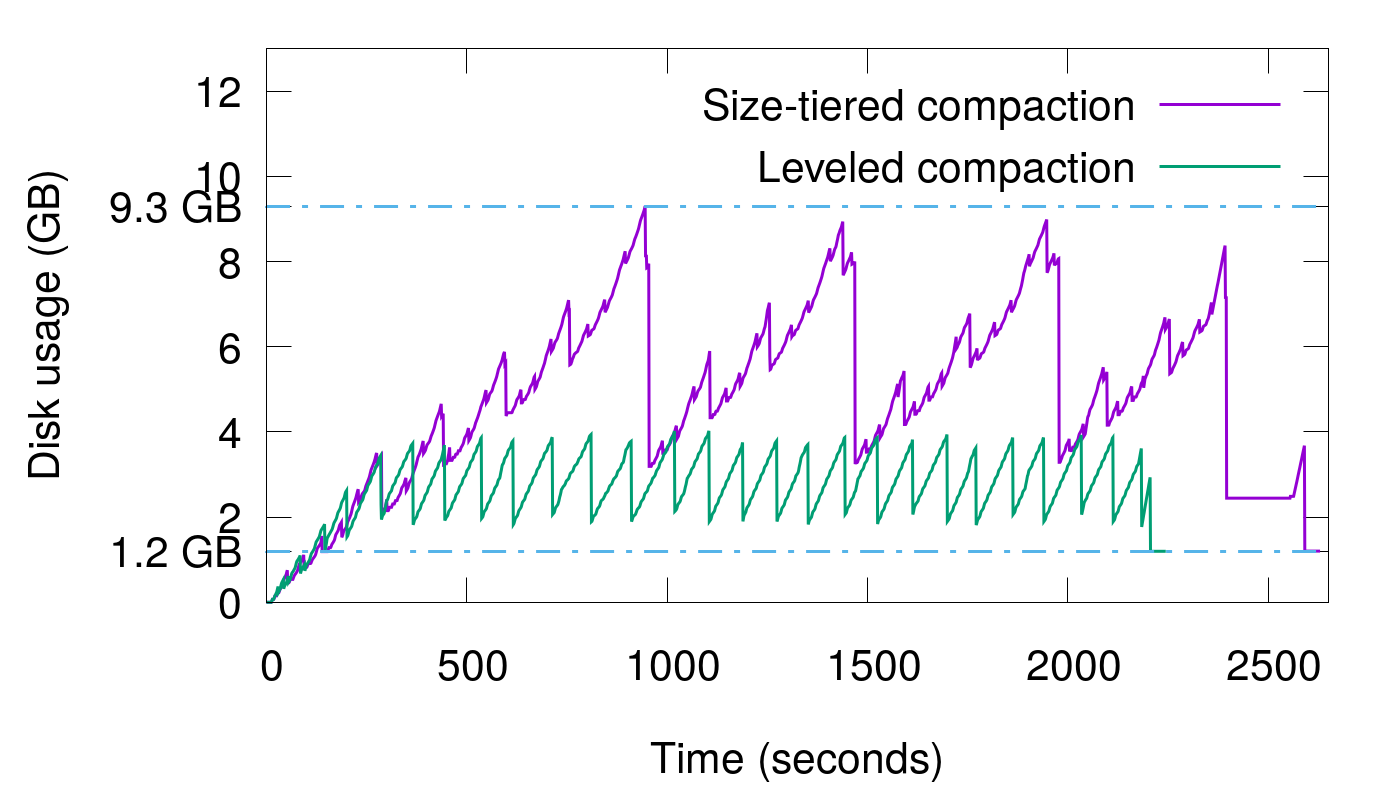
Voordat we aan ons debug-avontuur beginnen, laten we de feiten op een rijtje zetten:
Write amplification treedt op wanneer de hoeveelheid data die naar opslagmedia wordt geschreven groter is dan de hoeveelheid data die de applicatie van plan was te schrijven.
Met andere woorden, je database speelt een sluwe truc met je uit, door meer data te schrijven dan je hebt gevraagd. Dit gaat niet alleen over het verspillen van opslagruimte; het is een prestatievampier die de levensduur uit je I/O-operaties zuigt en je SSD's sneller verslijt dan een paar sneakers in een marathon.
De Verdachten: Cassandra en MongoDB
Laten we onze detectivehoeden opzetten en onderzoeken hoe write amplification zich manifesteert in twee populaire NoSQL-databases:
Cassandra: Het Compaction Dilemma
Cassandra, met zijn log-structured merge-tree (LSM-tree) opslagengine, is bijzonder gevoelig voor write amplification. Hier is waarom:
- Onveranderlijke SSTables: Cassandra schrijft data naar onveranderlijke SSTables, waardoor nieuwe bestanden worden gemaakt in plaats van bestaande te wijzigen.
- Compaction: Om deze bestanden te beheren, voert Cassandra compaction uit, waarbij meerdere SSTables worden samengevoegd tot één.
- Tombstones: Verwijderingen in Cassandra creëren tombstones, wat... je raadt het al, meer schrijfbewerkingen zijn!
Laten we een vereenvoudigd voorbeeld bekijken van hoe dit zich afspeelt:
-- Eerste schrijfopdracht
INSERT INTO users (id, name) VALUES (1, 'Alice');
-- Update (maakt een nieuwe SSTable)
UPDATE users SET name = 'Alicia' WHERE id = 1;
-- Verwijdering (maakt een tombstone)
DELETE FROM users WHERE id = 1;
In dit scenario kan een enkel gebruikersrecord meerdere keren worden geschreven over verschillende SSTables, wat leidt tot write amplification tijdens compaction.
MongoDB: De MMAP Chaos
MongoDB, vooral in de eerdere versies met de MMAP-opslagengine, had zijn eigen write amplification problemen:
- In-place Updates: MongoDB probeert documenten in-place bij te werken wanneer mogelijk.
- Documentgroei: Als een document groeit en niet in zijn oorspronkelijke ruimte past, wordt het herschreven naar een nieuwe locatie.
- Fragmentatie: Dit leidt tot fragmentatie, wat periodieke compaction vereist.
Hier is een MongoDB-voorbeeld dat kan leiden tot write amplification:
// Eerste invoeging
db.users.insertOne({ _id: 1, name: "Bob", hobbies: ["lezen"] });
// Update die het document laat groeien
db.users.updateOne(
{ _id: 1 },
{ $push: { hobbies: "skydiven" } }
);
Als "Bob" blijft hobby's toevoegen, kan het document zijn toegewezen ruimte ontgroeien, waardoor MongoDB het volledig moet herschrijven.
Debuggen van Write Amplification: Tools van het Vak
Nu we weten waar we mee te maken hebben, laten we ons bewapenen met enkele debugtools:
Voor Cassandra:
- nodetool cfstats: Deze opdracht geeft statistieken over SSTables, inclusief write amplification.
- nodetool compactionstats: Geeft real-time informatie over lopende compactions.
- JMX Monitoring: Gebruik tools zoals jconsole om Cassandra's JMX-metrics met betrekking tot compaction en SSTables te monitoren.
Hier is hoe je nodetool cfstats kunt gebruiken:
nodetool cfstats keyspace_name.table_name
Zoek naar de "Write amplification" metric in de output.
Voor MongoDB:
- db.collection.stats(): Geeft statistieken over een collectie, inclusief avgObjSize en storageSize.
- mongostat: Een command-line tool die real-time databaseprestatiestatistieken toont.
- MongoDB Compass: GUI-tool die visuele inzichten biedt in databaseprestaties en opslaggebruik.
Hier is een voorbeeld van het gebruik van db.collection.stats() in de MongoDB-shell:
db.users.stats()
Let op de verhouding tussen "size" en "storageSize" om mogelijke write amplification te beoordelen.
Het Temmen van het Write Amplification Beest
Nu we het probleem hebben geïdentificeerd, laten we eens kijken naar enkele oplossingen:
Voor Cassandra:
- Compactionstrategieën Afstemmen: Kies de juiste compactionstrategie voor je workload (SizeTieredCompactionStrategy, LeveledCompactionStrategy, of TimeWindowCompactionStrategy).
- Tombstoneverwerking Optimaliseren: Pas gc_grace_seconds aan en gebruik batchverwijderingen wanneer mogelijk.
- SSTables op de juiste grootte maken: Pas compaction_throughput_mb_per_sec en max_threshold instellingen aan.
Hier is een voorbeeld van het wijzigen van de compactionstrategie:
ALTER TABLE users WITH compaction = {
'class': 'LeveledCompactionStrategy',
'sstable_size_in_mb': 160
};
Voor MongoDB:
- Gebruik de WiredTiger Storage Engine: Deze is efficiënter in het omgaan met write amplification in vergelijking met MMAP.
- Documentvoorallocatie Implementeren: Als je weet dat een document zal groeien, reserveer dan vooraf ruimte ervoor.
- Regelmatige Compaction: Voer regelmatig het compact-commando uit om ruimte terug te winnen en fragmentatie te verminderen.
Voorbeeld van het uitvoeren van compaction in MongoDB:
db.runCommand( { compact: "users" } )
De Plotwending: Wanneer Write Amplification Eigenlijk Goed Is
Houd je toetsenborden vast, want hier wordt het interessant: soms kan write amplification voordelig zijn! In bepaalde scenario's kan het ruilen van extra schrijfbewerkingen voor betere leesprestaties een slimme zet zijn.
Bijvoorbeeld, in Cassandra vermindert compaction het aantal SSTables dat moet worden gecontroleerd tijdens het lezen, wat mogelijk de queryreacties versnelt. Evenzo kan het herschrijven van documenten in MongoDB leiden tot betere documentlokalisatie, wat de leesprestaties kan verbeteren.
De sleutel is om de juiste balans te vinden voor je specifieke gebruikssituatie. Het is als kiezen tussen een Zwitsers zakmes en een gespecialiseerd gereedschap – soms is de veelzijdigheid de extra bulk waard.
Afronden: Blijf Kalm en Debug Door
Write amplification in NoSQL-databases is als die ene vreemde bug die steeds weer opduikt in je code – vervelend, maar te overwinnen met de juiste aanpak. Door de oorzaken te begrijpen, de juiste debugtools te gebruiken en gerichte oplossingen te implementeren, kun je je database-schrijfbewerkingen onder controle houden en je opslagkosten binnen de perken houden.
Onthoud, elke database en workload is uniek. Wat voor de een werkt, werkt misschien niet voor de ander. Blijf experimenteren, meten en optimaliseren. En wie weet? Misschien word je wel de write amplification fluisteraar in je team.
Ga nu op pad en debug die wilde schrijfbewerkingen! Je SSD's zullen je dankbaar zijn.
"Debuggen is als de detective zijn in een misdaadfilm waar je ook de moordenaar bent." - Filipe Fortes
Succes met debuggen!