Bloomfilters zijn als de uitsmijters van de datawereld – ze vertellen je snel of iets waarschijnlijk in de club (jouw dataset) zit of zeker niet, zonder daadwerkelijk de deuren te openen. Deze probabilistische datastructuur kan onnodige zoekopdrachten en netwerkoproepen aanzienlijk verminderen, waardoor je systeem sneller en efficiënter wordt.
De Magie Achter de Schermen
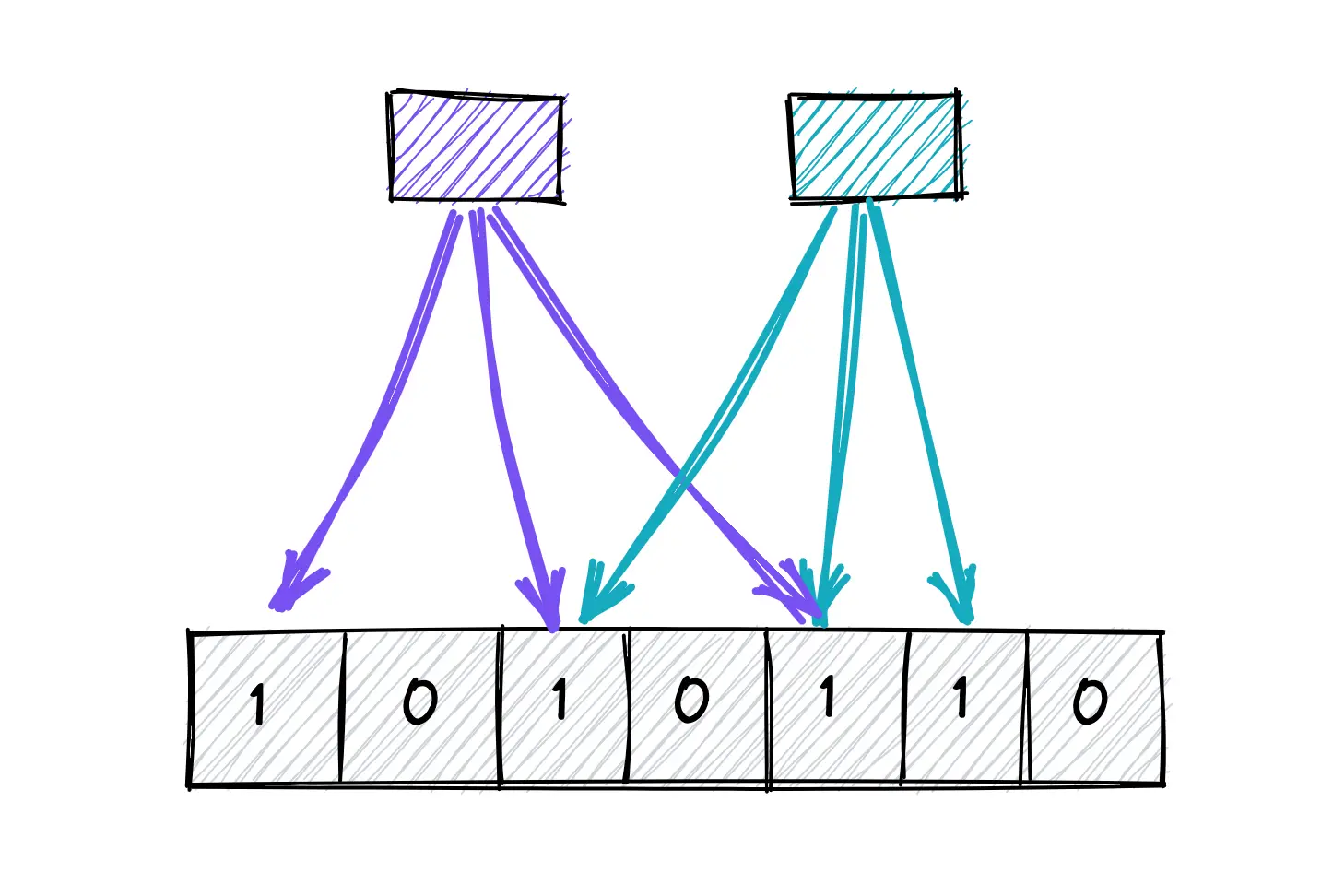
In de kern is een Bloomfilter een array van bits. Wanneer je een element toevoegt, wordt het meerdere keren gehasht en worden de overeenkomstige bits op 1 gezet. Controleren of een element bestaat, houdt in dat je het opnieuw hasht en kijkt of alle overeenkomstige bits zijn ingesteld. Het is eenvoudig, maar krachtig.
class BloomFilter:
def __init__(self, size, hash_count):
self.size = size
self.hash_count = hash_count
self.bit_array = [0] * size
def add(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
self.bit_array[index] = 1
def check(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
if self.bit_array[index] == 0:
return False
return True
Praktische Toepassingen: Waar Bloomfilters Uitblinken
Laten we eens kijken naar enkele praktische scenario's waarin Bloomfilters van pas kunnen komen:
1. Cachesystemen: De Poortwachter
Stel je voor dat je een grootschalig cachesysteem beheert. Voordat je de dure backend-opslag aanspreekt, kun je een Bloomfilter gebruiken om te controleren of de sleutel mogelijk in de cache bestaat.
def get_item(key):
if not bloom_filter.check(key):
return None # Zeker niet in cache
# Mogelijk in cache, laten we het controleren
return actual_cache.get(key)
Deze eenvoudige controle kan cache-missers en onnodige backend-queries drastisch verminderen.
2. Zoekoptimalisatie: De Snelle Eliminator
In een gedistribueerd zoeksysteem kunnen Bloomfilters fungeren als een voorfilter om onnodige zoekopdrachten over shards te elimineren.
def search_shards(query):
results = []
for shard in shards:
if shard.bloom_filter.check(query):
results.extend(shard.search(query))
return results
Door snel shards te elimineren die de query zeker niet bevatten, kun je het netwerkverkeer verminderen en de zoektijden verbeteren.
3. Duplicaatdetectie: De Efficiënte Deduplicator
Bij het crawlen van het web of het verwerken van grote datastromen is het snel detecteren van duplicaten cruciaal.
def process_item(item):
if not bloom_filter.check(item):
bloom_filter.add(item)
process_new_item(item)
else:
# Mogelijk eerder gezien, doe extra controle
pass
Deze aanpak kan het geheugengebruik aanzienlijk verminderen in vergelijking met het bijhouden van een volledige lijst van verwerkte items.
De Fijne Kneepjes: Je Bloomfilter Afstemmen
Net als elk goed gereedschap hebben Bloomfilters de juiste afstemming nodig. Hier zijn enkele belangrijke overwegingen:
- Grootte doet ertoe: Hoe groter het filter, hoe lager de kans op valse positieven, maar hoe meer geheugen het gebruikt.
- Hashfuncties: Meer hashfuncties verminderen valse positieven maar verhogen de rekentijd.
- Verwacht aantal items: Het kennen van je datagrootte helpt bij het optimaliseren van de parameters van het filter.
Hier is een snelle formule om je Bloomfilter te dimensioneren:
import math
def optimal_bloom_filter_size(item_count, false_positive_rate):
m = -(item_count * math.log(false_positive_rate)) / (math.log(2)**2)
k = (m / item_count) * math.log(2)
return int(m), int(k)
# Voorbeeldgebruik
items = 1000000
fp_rate = 0.01
size, hash_count = optimal_bloom_filter_size(items, fp_rate)
print(f"Optimale grootte: {size} bits")
print(f"Optimale hash-aantal: {hash_count}")
Valkuilen en Overwegingen
Voordat je helemaal losgaat met Bloomfilters, houd deze punten in gedachten:
- Valse positieven zijn een ding: Bloomfilters kunnen zeggen dat een item aanwezig is terwijl dat niet zo is. Plan hiervoor in je foutafhandeling.
- Geen verwijdering: Standaard Bloomfilters ondersteunen het verwijderen van items niet. Kijk naar Counting Bloom Filters als je deze functionaliteit nodig hebt.
- Geen wondermiddel: Hoewel krachtig, zijn Bloomfilters niet geschikt voor elk scenario. Evalueer je gebruikssituatie zorgvuldig.
"Met grote kracht komt grote verantwoordelijkheid. Gebruik Bloomfilters verstandig, en ze zullen je backend goed behandelen." - Oom Ben (als hij een softwarearchitect was)
Bloomfilters Integreren in Je Stack
Klaar om Bloomfilters uit te proberen? Hier zijn enkele populaire bibliotheken om je op weg te helpen:
- Guava voor Java-ontwikkelaars
- pybloom voor Python-liefhebbers
- bloomd voor een zelfstandige netwerkservice
Het Grotere Plaatje: Waarom Moeite Doen?
In het grote geheel zijn Bloomfilters meer dan alleen een slimme truc. Ze vertegenwoordigen een breder principe in systeemontwerp: soms kan een beetje onzekerheid leiden tot enorme prestatieverbeteringen. Door een kleine kans op valse positieven te accepteren, kunnen we systemen creëren die sneller, schaalbaarder en efficiënter zijn.
Stof tot Nadenken
Als je Bloomfilters in je architectuur implementeert, overweeg dan deze vragen:
- Hoe kan de probabilistische aard van Bloomfilters andere delen van je systeemontwerp beïnvloeden?
- In welke andere scenario's kan het ruilen van perfecte nauwkeurigheid voor snelheid voordelig zijn?
- Hoe past het gebruik van Bloomfilters binnen de SLA's en foutbudgetten van je systeem?
Afronding: De Bloei is Eraf
Bloomfilters zijn misschien niet de nieuwste rage, maar ze zijn een beproefd, robuust hulpmiddel dat een plek verdient in je backend-toolkit. Van caching tot zoekoptimalisatie, deze probabilistische krachtpatsers kunnen je gedistribueerde systemen de prestatieboost geven die ze nodig hebben.
Dus de volgende keer dat je wordt geconfronteerd met een datavloed of een querymoeras, onthoud: soms ligt de oplossing in bloei.
Ga nu en filter, jullie geweldige backend-meesters!